
Relevant paper: [C3].
In this work, we examine distributed deep learning setups in which computing devices may return adversarial or erroneous computations. This behavior is called Byzantine and is typically attributed to adversarial attacks on the nodes or failures/crashes thereof. As a result, the corresponding gradients are potentially unreliable for use in training and model updates. Achieving robustness in the face of Byzantine node behavior (which can cause gradient-based methods to converge slowly or converge to a bad solution) is of crucial importance and has attracted significant attention in the community. Our redundancy-based method ByzShield leverages the properties of bipartite expander graphs for assigning tasks to workers; this helps to effectively mitigate the effect of the Byzantine behavior.
We consider an omniscient adversary with full knowledge of the tasks assigned to the workers. The adversary is allowed to pick any subset of $q$ out of $K$ worker nodes to attack at each iteration of the algorithm. Our model allows for collusion among the Byzantine workers to inflict maximum damage on the training process. In addition, we test our method against the most sophisticated attacks in literature, among which is ALIE.
Our work demonstrates an interesting link between achieving robustness and spectral graph theory. Specifically, we demonstrate that using optimal expander graphs (constructed from mutually orthogonal Latin squares and Ramanujan graphs) allows us to assign redundant tasks to workers in such a way that the adversary’s ability to corrupt the gradients is significantly reduced as compared to the prior state of the art.
Our theoretical analysis shows that our method achieves a much lower fraction of corrupted gradients compared to other methods (DETOX, DRACO); this is supported by numerical simulations, which indicate over a 36% reduction on average in the fraction of corrupted gradients. Our experimental results on large-scale training for image classification (CIFAR-10) show that ByzShield has, on average, a 20% advantage in accuracy under the most sophisticated attacks.
The notation used here is the following
- $q$: number of adversarial devices.
- $c_{max}^{(q)}$: maximum number of distorted gradients a worst-case attack on ByzShield can distort.
- $\hat{\epsilon}$: fraction of distorted gradients achieved by each scheme.
- $\gamma$: upper bound on $c_{max}^{(q)}$ of ByzShield, derived in our paper.
Let us define a scheme that does not assign redundant gradient tasks to workers as baseline. A baseline scheme directly filters the gradients returned by the K workers. A redundancy-based scheme such as ByzShield, DETOX, and DRACO assigns multiple copies of each gradient computation to different workers. Then, majority voting is performed across all workers responsible for the same gradient. Finally, the outputs of the majority voting pass through one more step of filtering (e.g., coordinate-wise median) to decide the final gradient used for the model update.
A very useful metric that serves as a good indicator of the convergence of the model is the distorted gradients’ fraction $\hat{\epsilon}$, as defined above. A set of simulations on a cluster of $K=15$ servers is presented in Table 1. Since both DETOX and DRACO use the Fractional Repetition Code (FRC), we present them in a unified manner. Note that ByzShield enjoys a much lower $\hat{\epsilon}$ than other schemes in most cases.
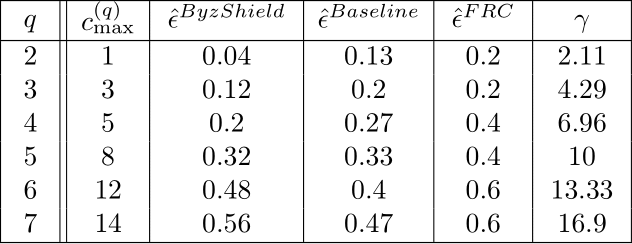 Table 1: Fraction of distorted gradients achieved by various schemes.
Table 1: Fraction of distorted gradients achieved by various schemes.
Some of our experimental results on CIFAR-10 using $K=25$ workers are shown in Figures 1 and 2. The metric is the top-1 test accuracy. Our method supersedes other schemes even for large values of $q$ (e.g., when $q=5$ out of the $K=25$ workers are under attack).
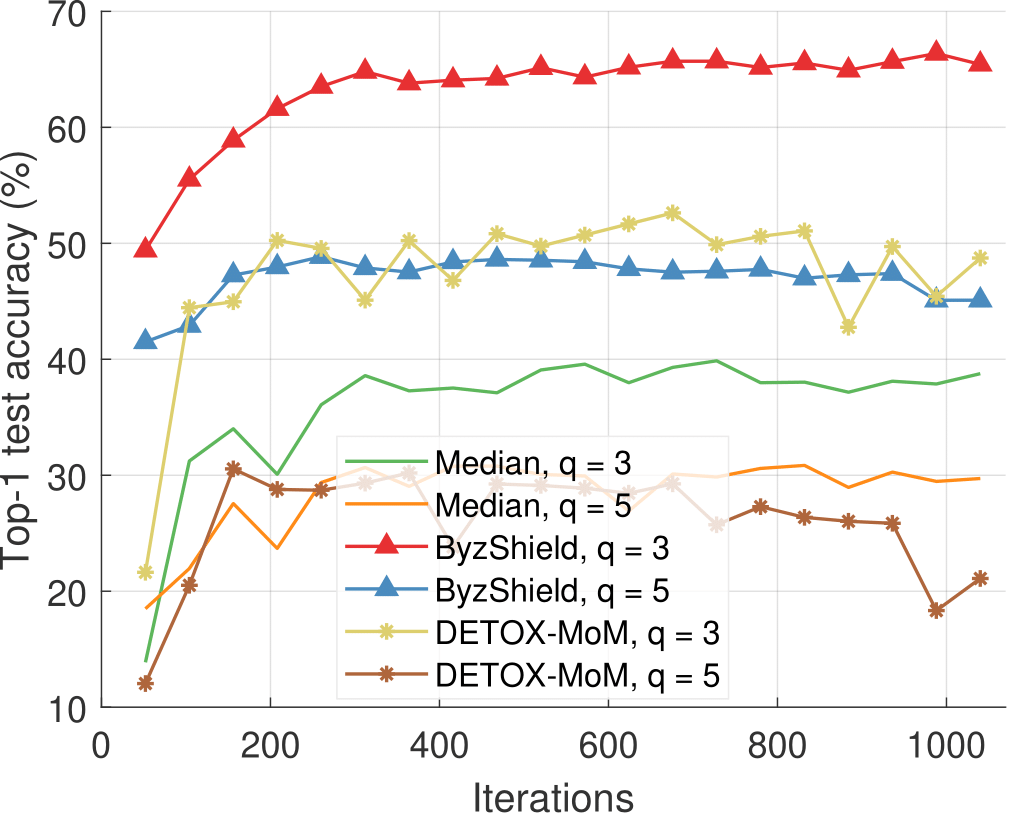 Figure 1: ALIE attack and median-based defenses (CIFAR-10).
Figure 1: ALIE attack and median-based defenses (CIFAR-10).
Figure 2: Constant attack and signSGD-based defenses (CIFAR-10).