
Big data analytics often require distributed implementations in which clusters process a sheer amount of data. Hadoop MapReduce and Apache Spark are examples of such frameworks. These systems perform initial processing during the Map phase, the machines communicate during the Shuffle phase, and a final computation is performed in the Reduce phase. Extensive evidence suggests that the Shuffle phase is rather time-intensive and can delay the entire algorithm.
Existing methods run multiple copies of each Map task on different servers and utilize coded transmissions to reduce the amount of data exchanged among the machines. The main issue of prior techniques is that they require the original job to be subdivided into a large number of Map tasks. This increases the encoding complexity and diminishes any promised gains. We show that one can simultaneously obtain low communication loads while ensuring that jobs do not need to be split too finely. Our approach explores the relation between the Map task assignment and resolvable designs.
We have obtained experimental results on AWS EC2 clusters for a widely known distributed algorithm, namely TeraSort. Our method demonstrates over 4.69x improvement in speedup over the baseline approach and more than 2.6x over the current state of the art. The data set is of size 12GB, and 16 servers were used. The main experimental results are presented in Table 1 and visualized in Figure 1. Table 1 reports the time with and without the memory allocation cost, which turns out to be significant on AWS.
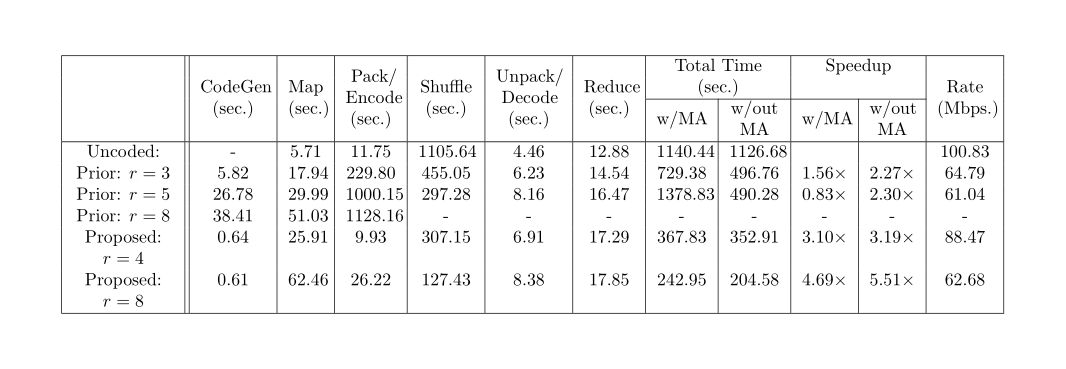 Table 1: MapReduce time for sorting 12GB data on 16 server nodes.
Table 1: MapReduce time for sorting 12GB data on 16 server nodes.
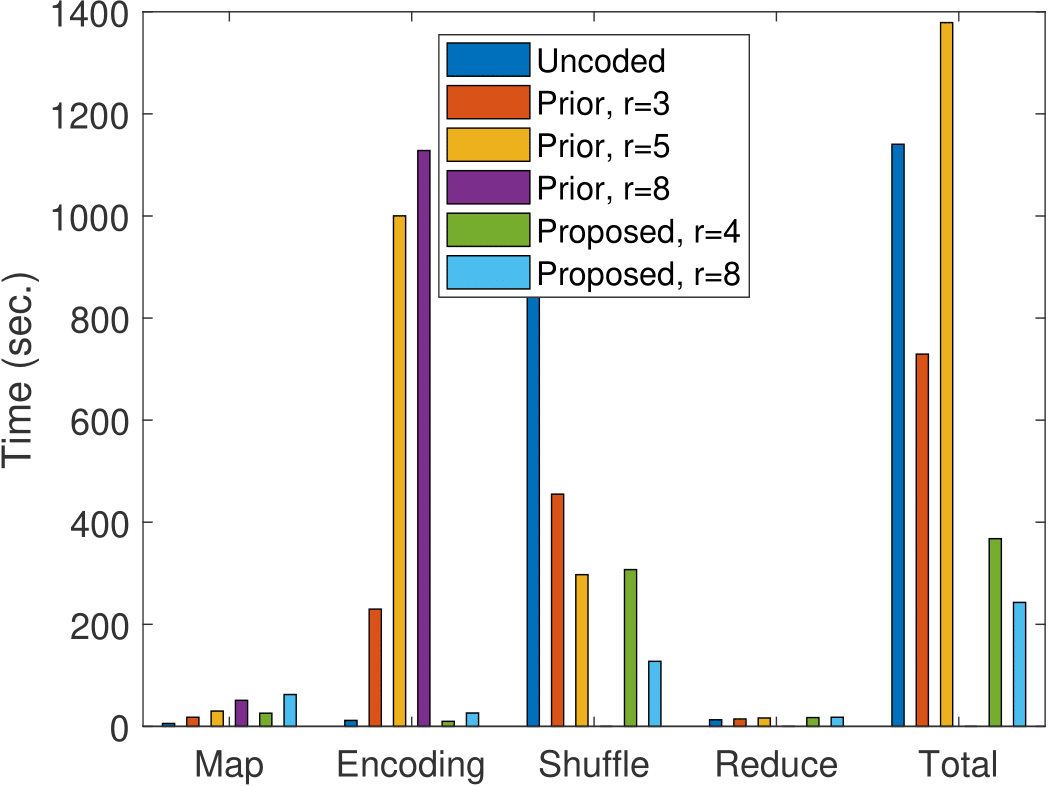 Figure 1: MapReduce time chart for sorting 12GB data on 16 server nodes.
Figure 1: MapReduce time chart for sorting 12GB data on 16 server nodes.